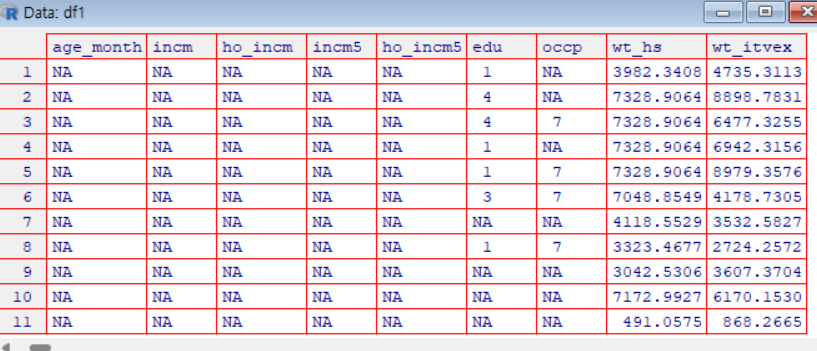
실제 데이터는 수집 과정에서 발생한 오류로 인해 결측치를 포함하고 있는 경우가 있다.
결측치가 존재하면 함수가 적용이 되지 않거나 분석 결과가 왜곡되는 문제가 발생한다.
따라서 데이터를 분석하기 전 결측치를 제거해주는 과정이 필요하다.
is.na()
is.na()함수는 NA값을 True로 그렇지 않은값을 False로 바꾸어주는 함수이다.
<사용법>
is.na(x) ##이때 x는 data.frame, 벡터, 행렬

일반적으로 dfnew = df[is.na(df$x) != T, ] 형식으로 결측치를 가진 데이터를 뽑아낸다.
complete.cases()
is.na()와 반대로 결측치 값을 False, 결측치가 아닌 값을 True로 반환한다.
is.na()와 달리 행단위로 함수가 적용된다.
<사용법>
complete.cases(x) ## x는 data.frame, 벡터, 행렬

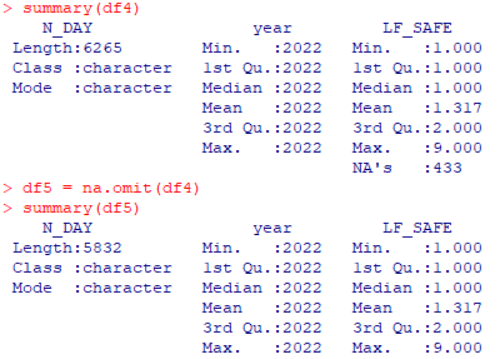
na.omit()
na.omit()은 위의 두 함수들 처럼 값을 논리형으로 변환하는것이 아닌 결측치가 있는행을 삭제시켜버리는 함수이다.
NA값이 있는 모든 행을 삭제하므로 사용에 주의가 필요하다.
<사용법>
na.omit(df) ##df는 data.frame

df4에 존재하던 433개의 결측치가 존재하는 행이 모두 삭제됨

'R 통계' 카테고리의 다른 글
| [R] 기본함수 - aggregate() (0) | 2024.10.15 |
|---|---|
| [R] dataframe과 열의 차이 (1) | 2024.10.15 |
| [R] 정규성 분석 (0) | 2024.10.12 |
| [R] 범주형 데이터와 그래프 (0) | 2024.10.12 |
| [R] 수치형 데이터와 그래프 (0) | 2024.10.12 |


